您現在的位置是:nhan dinh nong da >>正文
nhan dinh nong da
t? l? cá c??c bóng ?á indo93671人已圍觀
簡介文 丨 《BUG》欄目 周文猛DeepSeek又更新了,可惜仍不是萬眾期待的R2模型。此次DeepSeek線上模型版本已升級至V3.1。《BUG》欄目實測發現,升級后的DeepSeek在上下文長度和交...

文 丨 《BUG》欄目 周文猛
DeepSeek又更新了,可惜仍不是萬眾期待的R2模型。
此次DeepSeek線上模型版本已升級至V3.1。《BUG》欄目實測發現,升級后的DeepSeek在上下文長度和交互友好度上有明顯改進,編程能力受到推崇。在使用經濟性上,也有開發人員指出,“DeepSeek或將V3與R1模型進行了合并,這有利于降低模型部署成本。”
DeepSeek方面在回應《BUG》欄目時,直言“都以官方公布為準”。
巧合的是,今天是R1官方發布后的整7個月。在這期間,OpenAI、Google、阿里巴巴、月之暗面、智譜等紛紛發布了新模型,他們都以R1作為參照物。
而R2作為R1的后續產品,一直都是行業關注的焦點。大廠需要新的參照物,萬眾也在期待梁文鋒。

實測:上下文更長,性價比更高
在DeepSeek網頁端及最新版本App上,目前能夠支持的上下文長度已經擴展至最新的128K長度。
有開發者在深度體驗后發現,此次更新后,增加上下文相關內容,“穩定性更強了,推理能力也有了進步”。

《BUG》欄目對比發現,相較于此前發布的DeepSeek V3(參數量671B),此次更新V3.1(參數量685B),在模型尺寸上并未有過于明顯的變化。不過,在交互體驗感上,V3.1有了更明顯的提升。
除支持更大的長文本輸入外,在回答問題時,涉及信息收集的環節,DeepSeek會更多地使用表格進行信息匯總呈現,交互更友好,且回答內容更加符合人類表達習慣,語氣更加自然。
此外,在編程能力上,據網友曝出內容,DeepSeek V3.1在Aider Polyglot多語言編程測試中,以71.6%分舉擊敗了Claude 4 Opus,較DeepSeek R1也有進一步的提升。

《BUG》欄目實測發現,當以指令要求V3.1設計一個宮崎駿風格的五子棋游戲界面,并設有“人人對戰”和“人機對戰”兩個模擬按鈕,最終用2D插畫風格html呈現時,V3.1不僅能夠給出完整的設計過程和代碼結果,同時還支持在線運行演示,給出的結果也已具備交互模式,且編碼結果也基本接近可實用程度。
模型能力外,《BUG》欄目注意到,在最新的Deenhan dinh nong dapSeek App和官網上,更新后的DeepSeek,輸入框中的“深度思考(R1)”按鈕,直接變成了“深度思考”。
這意味著——在開啟深度思考模式后,DeepSeek調用的推理模型或已不再只局限于R1模型,也有可能是其他的新模型,或者是V3/R1合并后的新模型。

有開發者也注意到了這一變化,并且在研究測試后指出,“此次更新將V3和R1進行了合并部署,使得部署DeepSeek的簡易程度和算力效率得到了極大提升。”
該開發人員對《BUG》欄目解釋道:“之前V3、R1是分開部署的,各需要60張卡,現在是R1、V3合一,只需部署一個。原來要用120張卡現在60張卡就行,部署的成本大幅度下降了。”他進一步解釋道,“如果用120張卡部署V3.1,由于緩存增大,性能預估可提升3-4倍。”
在該開發人員看來,“此次更新,V 3.1更多的是一個技術前沿模型,主要針對降本。”
目前,在Huggingface(知名AI開源社區)上,最新更新的DeepSeek-V3.1-Base版本已經開放源代碼。不過,此次官方并未給出具體信息,只簡單提及該模型尺寸為685B,支持BF16、F8_E4M3、F32數據類型。
國內廠商期待新“參照物”
遺憾的是,此次V3.1更新,雖然在用戶體驗和經濟性上帶來了一些驚喜,但業界備受關注的新一代R2模型并未出現。
今年1月,伴隨DeepSeek R1發布并迅速引發各界關注,業界對DeepSeek的推崇與好感度迅速提升。在DeepSeek R1發布當月,DeepSeek網頁及App用戶增長達1.25億(含網站和應用累加),其中80%以上用戶來自1月最后一周。至今年1月28日,DeepSeek日活躍用戶數(DAU)首次超越豆包,成為全球增速最快的AI應用之一。
很快,其主動開放源代碼的做法,也讓業界開始借鑒或直接將DeepSeek滿血版集成到自己應用上,騰訊元寶、百度、360等新產品應運而生。
緊接著,各大廠商上演了“車輪戰”,眾人將R1作為是否成功的參照物。
國內方面,阿里巴巴旗下Qwen基本保持了每月一大發布,兩周一小發布的頻率,高頻發布全尺寸、多模態模型。nhan dinh nong da阿里上個月發布的千問3旗艦模型Qwen3-235B-A22B,聲稱在核心能力測評中,比肩Gemini-2.5 pro、o4-mini等頂尖閉源模型,并超越了DeepSeek R1。
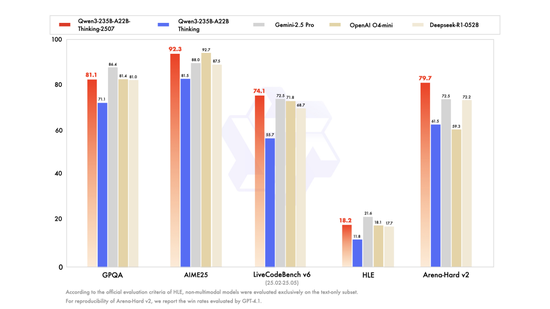
此外,月之暗面7月發布的Kimi K2 模型,以及智譜最新發布的新一代旗艦模型GLM-4.5,也先后宣布超越DeepSeek R1,且在使用經濟性上帶來新的突破,API調用價格低至輸入0.8元/百萬tokens。
梁文鋒,正在忙什么?
在與《BUG》欄目溝通中,DeepSeek方面并未透露更多后續發布的消息,對于R2何時發布等問題也僅回復稱:“詳細內容以官方公布為準”。
不過,接近DeepSeek人士曾透露,“DeepSeek-R2在8月內并無發布計劃。”這或許意味著,V3.1模型更新后,8月或將不會有更大版本的DeepSeek新模型發布。
此前,聯想創投集團高級合伙人宋春雨曾與梁文鋒有過深度交流,兩人關系熟絡。
近期,宋春雨在與《BUG》欄目溝通中感慨道:“他(梁文鋒)對商業化不感興趣,對留住用戶可能也不太感興趣”。在他看來,“梁文鋒是堅信AGI的人,是技術極客背景出身,他給自己的使命是要摸AGI的上限在哪里?甚至人類能達到硅基智能的上限究竟是什么?他專注的是打磨基礎模型,確保每一代模型都保持領先。”
但越是這樣,市場對于DeepSeek的期待值也愈發強烈。
在業內人士看來,“時至今日,各大AI模型的能力上限都已經很強了,需要做的是下限不要太低,能夠穩定輸出就是好模型。”
回想OpenAI旗下的GPT-5,同樣經歷了延遲發布,可惜最終發布的產品飽受詬病。主要原因就是數據、算力等方面的局限,AI大模型的能力上限或許已經不會有太多提升。
下一步,如何在經濟性、可用性等方面作出更多的創新,或許將成為檢驗大模型能力強弱的關鍵。
“此次V3、R1做了合并部署,或許是為DeepSeek多模態模型的發布作出準備,因為多模態分開部署推理和非推理負擔會很重。”在業內人士看來,V3.1發布后,“DeepSeek多模態模型發布的時間已經不遠了。”
熱鬧非凡的國內AI大模型市場,已許久不見DeepSeek和梁文鋒的“爆炸性”新聞,但市場對于它們的期待仍在不斷積蓄。
 海量資訊、精準解讀,盡在新浪財經APP
海量資訊、精準解讀,盡在新浪財經APP 責任編輯:楊賜
Tags:
相關文章
老廟黃金向五月天阿信旗下品牌STAYREAL致歉:已刪除相關頁面,不會再在市場出現類似商品
nhan dinh nong da近日,知名黃金品牌老廟黃金因產品“吉果樂園”造型“擦邊”STAYREAL魔魔胡胡胡蘿卜卜卜),引發消費者困惑與爭議。事件曝光后,老廟黃金于8月26日發布致歉信,承認工作失誤并向合作方STAYREAL及...
閱讀更多
蔚來李斌:過去十年充換電投入超180億,全國已建超8100座充換電站
nhan dinh nong da新浪科技訊 8月21日晚間消息,蔚來全新ES8產品技術發布會召開,蔚來創始人李斌發表開場演講。他表示,318充換電路線的建設,是蔚來過去十年在充換電領域堅決、持續投入的縮影。過去十年,蔚來在充換電領域...
閱讀更多
猛瑪宣布全球化戰略升級:實現品牌形象一體化,已布局160多個國家和地區
nhan dinh nong da新浪科技訊 8月26日晚間消息,無線音視頻品牌 HOLLYLAND 猛瑪今日舉辦品牌戰略暨秋季新品發布會,宣布其全球化戰略全面升級,將“MOMA猛瑪”與“HOLLYLAND”統一為“HOLLYLAND...
閱讀更多